1 - Álgebra Linear
Álgebra linear é o ramo da matemática que estuda vetores, matrizes, transformações lineares e sistemas de equações lineares. Seu objetivo é descrever estruturas em que combinações lineares desempenham papel central, permitindo modelar relações entre grandezas de forma compacta e rigorosa.
Historicamente, a área surgiu da necessidade de resolver sistemas de equações e de representar problemas geométricos e físicos por meio de coordenadas. Com o tempo, passou a fornecer uma linguagem unificada para tratar espaços vetoriais, mudanças de base, projeções, operadores e propriedades espectrais.
Esse campo é fundamental em matemática, física, estatística, economia e engenharia, mas tem importância especial em ciência da computação. Computação gráfica, visão computacional, aprendizado de máquina, otimização, simulação numérica, processamento de sinais e análise de redes dependem intensamente de conceitos de álgebra linear.
Ao longo deste capítulo, os tópicos serão apresentados em uma progressão que vai dos sistemas lineares e espaços vetoriais até transformações lineares, diagonalização, produto interno, projeções e formas canônicas. A intenção é construir uma base conceitual que seja útil tanto para o entendimento teórico quanto para aplicações computacionais.
Um sistema de equações lineares é um conjunto de equações em que as incógnitas aparecem apenas com expoente 1 e não são multiplicadas entre si. O objetivo é encontrar valores para essas incógnitas que satisfaçam simultaneamente todas as equações do sistema.
Em um sistema com $n$ incógnitas, normalmente precisamos de informações suficientes para determinar uma solução única. Isso depende não apenas da quantidade de equações, mas também de sua independência linear e da consistência do sistema. Em alguns casos, pode haver uma única solução, infinitas soluções ou nenhuma solução.
Um sistema linear pode ser escrito de maneira geral na forma
$$ \begin{cases} a_{11}x_1+a_{12}x_2+\cdots+a_{1n}x_n=b_1 \\ a_{21}x_1+a_{22}x_2+\cdots+a_{2n}x_n=b_2 \\ \vdots \\ a_{m1}x_1+a_{m2}x_2+\cdots+a_{mn}x_n=b_m \end{cases} $$Os números $a_{ij}$ são os coeficientes do sistema, $x_1,\ldots,x_n$ são as incógnitas e $b_1,\ldots,b_m$ são os termos independentes. Essa escrita deixa claro que o problema é combinar linearmente as incógnitas para produzir os valores desejados no lado direito.
Também é comum representar o sistema em forma matricial:
$$ A\vec{x}=\vec{b} $$Nessa notação, $A$ é a matriz dos coeficientes, $\vec{x}$ é o vetor das incógnitas e $\vec{b}$ é o vetor dos termos independentes. Essa representação é importante porque transforma um conjunto de equações em um único objeto algébrico, permitindo o uso de matrizes, determinantes e operações elementares.
Do ponto de vista geométrico, cada equação linear representa uma reta no plano, um plano no espaço ou, em dimensões maiores, um hiperplano. Resolver o sistema é encontrar a interseção desses objetos geométricos. Se a interseção for um único ponto, temos solução única. Se for uma reta ou uma região com vários pontos, temos infinitas soluções. Se não houver interseção comum, o sistema é incompatível.
Assim, os sistemas lineares costumam ser classificados em:
- sistema possível e determinado, quando existe exatamente uma solução;
- sistema possível e indeterminado, quando existem infinitas soluções;
- sistema impossível, quando não existe solução.
Quando o número de equações é pequeno, duas estratégias elementares são bastante úteis para entender a mecânica da solução.
Substituição: isolamos uma variável em uma equação e a substituímos nas demais. Por exemplo:
$$ y=2-x \\ 4x+y=2\\ ---------\\ 4x+(2-x)=2\\ 3x+2=2\\ x=0 \Rightarrow y=2 $$Esse método é especialmente útil quando uma variável pode ser isolada com facilidade. Ele reduz o número de incógnitas do problema e transforma o sistema original em outro mais simples.
Eliminação: combinamos equações de modo a eliminar uma incógnita e reduzir o sistema. Por exemplo:
$$ 3x-y=7 \quad [1]\\ 2x+y=8 \quad [2]\\ = 5x+0y=7+8 \Rightarrow x=3\\ \Rightarrow 3(3)-y=7 \Rightarrow 9-y=7 \Rightarrow y=2 $$Nesse caso, somamos as duas equações porque os coeficientes de $y$ são opostos. O resultado é uma nova equação equivalente, mas com menos incógnitas efetivas. Esse é o princípio central dos métodos de eliminação.
Para sistemas maiores, o procedimento padrão é a eliminação de Gauss. A ideia é trabalhar com a matriz aumentada do sistema:
$$ \left[ \begin{array}{ccc|c} a_{11} & a_{12} & \cdots & b_1 \\ a_{21} & a_{22} & \cdots & b_2 \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & b_m \end{array} \right] $$Em seguida, aplicamos operações elementares nas linhas, que preservam o conjunto de soluções:
- trocar duas linhas de posição;
- multiplicar uma linha por uma constante não nula;
- somar a uma linha um múltiplo de outra linha.
O objetivo é transformar a matriz em forma escalonada. Nessa forma, as primeiras entradas não nulas de cada linha aparecem progressivamente mais à direita, o que torna o sistema muito mais simples de resolver.
Considere, por exemplo, o sistema
$$ \begin{cases} x+y+z=6 \\ 2x-y+z=3 \\ x+2y-z=3 \end{cases} $$Sua matriz aumentada é
$$ \left[ \begin{array}{ccc|c} 1 & 1 & 1 & 6 \\ 2 & -1 & 1 & 3 \\ 1 & 2 & -1 & 3 \end{array} \right] $$Agora eliminamos os termos abaixo do primeiro pivô:
$$ L_2\leftarrow L_2-2L_1,\qquad L_3\leftarrow L_3-L_1 $$ $$ \left[ \begin{array}{ccc|c} 1 & 1 & 1 & 6 \\ 0 & -3 & -1 & -9 \\ 0 & 1 & -2 & -3 \end{array} \right] $$Depois eliminamos o termo abaixo do segundo pivô. Uma forma simples é combinar as linhas $L_2$ e $L_3$:
$$ L_3\leftarrow 3L_3+L_2 $$ $$ \left[ \begin{array}{ccc|c} 1 & 1 & 1 & 6 \\ 0 & -3 & -1 & -9 \\ 0 & 0 & -7 & -18 \end{array} \right] $$Chegamos a uma forma triangular. A partir daqui usamos retro-substituição:
$$ -7z=-18 \Rightarrow z=\frac{18}{7} $$ $$ -3y-z=-9 \Rightarrow -3y-\frac{18}{7}=-9 \Rightarrow y=\frac{15}{7} $$ $$ x+y+z=6 \Rightarrow x+\frac{15}{7}+\frac{18}{7}=6 \Rightarrow x=\frac{9}{7} $$Logo, a solução do sistema é
$$ \left(x,y,z\right)=\left(\frac{9}{7},\frac{15}{7},\frac{18}{7}\right) $$O papel dos pivôs é importante: eles indicam quais variáveis podem ser resolvidas diretamente em cada etapa. Quando uma linha inteira de coeficientes zera e o termo independente permanece não nulo, como em
$$ 0x+0y+0z=5, $$concluímos que o sistema é impossível. Quando uma linha inteira zera, inclusive o termo independente, isso sinaliza dependência entre equações e pode indicar infinitas soluções.
Em problemas computacionais, a eliminação de Gauss é um dos algoritmos mais importantes da álgebra linear numérica. Ela serve não apenas para resolver sistemas, mas também para calcular posto de matrizes, encontrar inversas e investigar dependência linear entre vetores.
Quando passamos do cálculo manual para a implementação em computador, surgem preocupações adicionais. A primeira delas é o custo computacional. Para um sistema quadrado $n\times n$, a eliminação de Gauss exige, em ordem de grandeza, cerca de $O(n^3)$ operações aritméticas. Isso é perfeitamente viável para sistemas moderados, mas se torna caro quando $n$ é muito grande.
Outra preocupação é a estabilidade numérica. Em um computador, números reais são representados de forma aproximada, e cada operação pode introduzir pequenos erros de arredondamento. Ao longo de muitas etapas de eliminação, esses erros podem se acumular e degradar a qualidade da solução.
Por esse motivo, é comum usar pivotamento. A ideia é reorganizar as linhas para evitar divisões por números muito pequenos, que ampliam erros numéricos. No pivotamento parcial, escolhemos como pivô o maior elemento em valor absoluto da coluna corrente, trocando linhas quando necessário. Esse procedimento simples já melhora bastante a robustez do algoritmo.
Em software científico, também é comum separar a resolução do sistema em duas fases. Primeiro, a matriz é fatorada; depois, a solução é obtida por substituições sucessivas. Um exemplo importante é a fatoração LU, em que escrevemos
$$ A=LU $$onde $L$ é triangular inferior e $U$ é triangular superior. Em vez de refazer toda a eliminação a cada novo vetor $\vec{b}$, podemos resolver
$$ L\vec{y}=\vec{b} \qquad \text{e depois} \qquad U\vec{x}=\vec{y} $$Isso é especialmente útil quando a matriz $A$ permanece fixa e precisamos resolver vários sistemas com diferentes termos independentes.
Para sistemas muito grandes e esparsos, isto é, matrizes com muitos elementos nulos, métodos diretos como Gauss nem sempre são a melhor escolha. Nesses casos, aparecem métodos iterativos, como Jacobi, Gauss-Seidel e gradientes conjugados. Em vez de encontrar a solução exata em um número finito de passos algébricos, esses métodos constroem aproximações sucessivas que convergem para a solução sob certas condições.
A ideia de um método iterativo é começar com uma estimativa inicial $\vec{x}^{(0)}$ e gerar uma sequência
$$ \vec{x}^{(0)},\vec{x}^{(1)},\vec{x}^{(2)},\ldots $$que se aproxima da solução verdadeira. Isso é muito útil em problemas de grande escala, nos quais o armazenamento da matriz e o custo de fatoração seriam proibitivos.
Esses métodos têm papel central em computação científica, simulação e aprendizado de máquina. Sempre que um problema físico ou estatístico é discretizado, é comum que o resultado final seja um grande sistema linear.
As aplicações são numerosas. Em computação gráfica, sistemas lineares aparecem em transformação geométrica, iluminação, reconstrução de superfícies e simulação física. Em redes e circuitos elétricos, surgem ao aplicar as leis de Kirchhoff. Em processamento de imagens, aparecem em filtragem, reconstrução e remoção de ruído. Em aprendizado de máquina e estatística, estão por trás de regressão linear, mínimos quadrados e várias etapas de otimização.
Em modelagem de fenômenos físicos, como transferência de calor, escoamento de fluidos, elasticidade e propagação de ondas, equações diferenciais são frequentemente discretizadas por métodos numéricos, produzindo sistemas lineares de grande porte. Resolver esses sistemas de forma eficiente é uma das tarefas centrais da computação aplicada.
Do ponto de vista de ciência da computação, o estudo de sistemas lineares também envolve análise de algoritmos, estruturas de dados para matrizes esparsas, paralelismo e uso de bibliotecas numéricas. Em aplicações reais, não basta apenas saber que a solução existe; é preciso escolher um método que seja rápido, estável e compatível com o formato dos dados.
Um espaço vetorial é um conjunto no qual podemos somar elementos e multiplicá-los por escalares, preservando uma coleção de propriedades algébricas. Intuitivamente, ele generaliza o comportamento dos vetores usuais do plano e do espaço para outros objetos, como sequências, matrizes e funções.
A ideia mais importante aqui é que o termo vetor não precisa significar apenas uma seta geométrica. Em álgebra linear, vetor é qualquer objeto que possa ser combinado linearmente com outros do mesmo tipo. Assim, coordenadas numéricas, polinômios, matrizes, sinais discretos e funções podem ser tratados dentro da mesma estrutura abstrata.
Exemplos clássicos são $\mathbb{R}^3$, o conjunto das ternas ordenadas de números reais; $\mathbb{R}^n$, o conjunto das $n$-uplas reais; e $F(I)$, o conjunto das funções reais definidas em um intervalo $I\subset \mathbb{R}$. Em todos esses casos, a soma e a multiplicação por escalar devem satisfazer:
- $\forall\;u,v,w \in E \quad (u+v)+w=u+(v+w)$
- $\forall\;u,v\in E \quad u+v=v+u$
- $\exists\;0\in E\;|\;\forall u\in E\quad u+0=0+u$
- $\forall\;u\in E,\exists\;(-u)\in E\;|\;u+(-u)=(-u)+u=0$
- $\forall\;\alpha,\beta\in R,\;\forall\;u,v\in E \; \alpha(u+v)=\alpha u+\alpha v$
- $\forall\;\alpha,\beta \in R,\; \forall\;u \in E \quad (\alpha +\beta)u=\alpha u+\beta u$
- $\forall\;\alpha,\beta \in R,\;\forall\;u\in E \quad \alpha(\beta u)=(\alpha \beta)u$
- $\forall\;u \in E \quad 1u=u$
Essas propriedades garantem que os cálculos com vetores se comportem de maneira consistente. Elas formalizam ideias intuitivas como poder agrupar somas sem alterar o resultado, trocar a ordem de parcelas, usar um vetor nulo e escalar vetores sem quebrar a estrutura do conjunto.
Do ponto de vista operacional, um espaço vetorial é o ambiente em que faz sentido escrever expressões como
$$ \alpha_1v_1+\alpha_2v_2+\cdots+\alpha_kv_k $$Essas expressões são chamadas combinações lineares. Toda a álgebra linear gira em torno de entender quais objetos podem ser obtidos a partir de combinações lineares de outros, quais conjuntos geram um espaço e como representar vetores de maneira eficiente.
Em $\mathbb{R}^2$, por exemplo, se tomarmos os vetores $u=(1,0)$ e $v=(0,1)$, então qualquer vetor $(a,b)$ pode ser escrito como
$$ (a,b)=a(1,0)+b(0,1) $$Isso mostra que dois vetores apropriados já são suficientes para gerar todo o plano. O mesmo raciocínio vale para $\mathbb{R}^3$, $\mathbb{R}^n$ e muitos outros espaços mais abstratos.
Também é importante perceber que nem todo conjunto com objetos semelhantes forma um espaço vetorial. Se um conjunto não for fechado por soma ou por multiplicação por escalar, ele falha como espaço vetorial. Por exemplo, o conjunto dos vetores de $\mathbb{R}^2$ com ambas as coordenadas positivas não é um espaço vetorial, porque o produto por um escalar negativo produz vetores fora do conjunto.
Outro exemplo instrutivo é o conjunto de polinômios reais de grau menor ou igual a 2:
$$ P_2=\{a_0+a_1x+a_2x^2 \mid a_0,a_1,a_2\in\mathbb{R}\} $$Esse conjunto é um espaço vetorial, porque a soma de dois polinômios de grau no máximo 2 continua tendo grau no máximo 2, e o produto por escalar preserva essa propriedade. Além disso, qualquer elemento de $P_2$ pode ser escrito como combinação linear de $1$, $x$ e $x^2$.
De forma semelhante, o conjunto das matrizes reais $m\times n$ forma um espaço vetorial quando usamos soma de matrizes e multiplicação por escalar definidas entrada a entrada. Isso mostra como a noção de espaço vetorial unifica objetos geométricos, algébricos e computacionais sob o mesmo formalismo.
Uma das razões pelas quais espaços vetoriais são tão importantes é que eles permitem separar estrutura de representação. Quando dizemos que dois problemas diferentes vivem em espaços vetoriais, muitas técnicas passam a valer para ambos: mudança de base, projeção, decomposição, diagonalização e resolução numérica.
Na prática, essa abstração aparece em inúmeras aplicações. Em computação gráfica, pontos, direções, cores e transformações podem ser descritos por vetores e matrizes. Em aprendizado de máquina, cada amostra de dados costuma ser representada como um vetor de atributos. Em processamento de sinais, um sinal discreto pode ser tratado como um vetor de amplitudes. Em processamento de linguagem natural, palavras, frases e documentos são frequentemente embutidos em espaços vetoriais de alta dimensão.
Em ciência de dados e estatística, pensar em dados como vetores permite medir distâncias, projetar informações, reduzir dimensionalidade e ajustar modelos lineares. Em simulação numérica, funções aproximadas e estados físicos discretizados também passam a ser representados em espaços vetoriais, o que possibilita o uso de algoritmos matriciais.
Na prática, as propriedades de espaço vetorial permitem falar em combinação linear, dependência linear, base, dimensão e transformações lineares, que são os conceitos centrais da álgebra linear. Quase todos os demais tópicos do capítulo dependem dessa estrutura de fundo.
Um subconjunto $S$ de um espaço vetorial $V$ é chamado subespaço vetorial de $V$ se:
- O vetor nulo de $V$ pertence a $S$;
- Se os vetores $u$ e $v$ de $V$ estão em $S$, então $u+v$ também pertence a $S$;
- Se o vetor $u$ de $V$ está em $S$ e $\lambda\in R$ é um escalar qualquer, então $\lambda u$ também pertence a $S$.
Em outras palavras, um subespaço é uma parte de um espaço vetorial que continua sendo, por si só, um espaço vetorial quando usamos as mesmas operações herdadas do espaço original. A importância desse conceito está em identificar regiões estruturadas dentro de espaços maiores, nas quais ainda podemos aplicar toda a linguagem da álgebra linear.
Os três critérios acima expressam, respectivamente, a presença do vetor nulo e o fechamento por soma e por multiplicação por escalar. O fechamento é a ideia central: sempre que combinamos elementos de $S$ usando as operações lineares permitidas, o resultado precisa continuar em $S$.
Na prática, costuma-se usar um critério equivalente bastante útil: um subconjunto não vazio $S\subseteq V$ é subespaço se, para quaisquer $u,v\in S$ e quaisquer escalares $\alpha,\beta$, tivermos
$$ \alpha u+\beta v \in S $$Esse teste concentra as propriedades de fechamento em uma única condição e simplifica muitas demonstrações.
Exemplo: no espaço $\mathbb{R}^2$, o conjunto
$$ S=\{(x,y)\in \mathbb{R}^2 \mid y=2x\} $$é um subespaço. De fato, ele contém o vetor nulo, pois $(0,0)$ satisfaz a equação $y=2x$. Além disso, se $(x_1,2x_1)$ e $(x_2,2x_2)$ pertencem a $S$, então
$$ (x_1,2x_1)+(x_2,2x_2)=(x_1+x_2,2x_1+2x_2)=(x_1+x_2,2(x_1+x_2)) $$que continua em $S$. Finalmente, para qualquer escalar $\lambda$,
$$ \lambda(x,2x)=(\lambda x,2\lambda x) $$também pertence a $S$. Geometricamente, esse subespaço é uma reta que passa pela origem.
Esse detalhe geométrico é importante: em $\mathbb{R}^2$ e $\mathbb{R}^3$, retas e planos que passam pela origem são candidatos naturais a subespaços. Já retas e planos que não passam pela origem não são subespaços, porque não contêm o vetor nulo.
Por exemplo, o conjunto
$$ T=\{(x,y)\in \mathbb{R}^2 \mid y=2x+1\} $$não é um subespaço de $\mathbb{R}^2$, pois a reta correspondente não passa pela origem. Basta observar que $(0,0)\notin T$.
Outro exemplo importante é o conjunto das soluções de um sistema linear homogêneo. Se
$$ A\vec{x}=\vec{0}, $$então o conjunto de todas as soluções forma um subespaço vetorial. Isso ocorre porque a soma de duas soluções ainda é solução, e o produto de uma solução por um escalar também continua sendo solução. Esse fato é central no estudo de núcleos de transformações lineares.
Subespaços também aparecem naturalmente como conjuntos gerados por vetores. Dado um conjunto de vetores $v_1,\ldots,v_k$, o conjunto de todas as combinações lineares desses vetores, chamado espaço gerado, é um subespaço:
$$ \text{span}(v_1,\ldots,v_k)=\{\alpha_1v_1+\cdots+\alpha_kv_k \mid \alpha_1,\ldots,\alpha_k\in \mathbb{R}\} $$Esse é, de fato, o menor subespaço que contém todos os vetores dados. Assim, sempre que queremos construir um subespaço a partir de vetores conhecidos, usamos seu conjunto gerado.
Considere, por exemplo, em $\mathbb{R}^3$, os vetores $v_1=(1,0,1)$ e $v_2=(0,1,1)$. O conjunto
$$ \text{span}(v_1,v_2) $$é um subespaço de $\mathbb{R}^3$ formado por todas as combinações lineares desses dois vetores. Geometricamente, ele corresponde a um plano passando pela origem, desde que $v_1$ e $v_2$ sejam linearmente independentes.
Em computação e matemática aplicada, subespaços aparecem o tempo todo: o espaço coluna de uma matriz, o espaço linha, o núcleo de uma transformação linear, os espaços de soluções de sistemas homogêneos, os subespaços gerados por bases reduzidas e os espaços usados em aproximação numérica e redução de dimensionalidade.
Em algoritmos de álgebra linear, verificar se certos vetores pertencem a um subespaço ou projetar dados sobre um subespaço são tarefas fundamentais. Em aprendizado de máquina, por exemplo, muitos métodos podem ser interpretados como busca de subespaços relevantes para representar dados de forma mais compacta.
Seja $\mathcal{B}$ um conjunto de vetores. Dizemos que ele é uma base de um espaço vetorial $V$ se:
- gera $V$ e;
- é linearmente independente.
Gerar $V$ significa que qualquer vetor do espaço pode ser escrito como combinação linear dos vetores da base. Já a independência linear garante que essa representação não tenha redundâncias. Em dimensão finita, uma base fornece um sistema de coordenadas para descrever cada vetor do espaço.
Essas duas condições se complementam. Se um conjunto gera o espaço, mas é linearmente dependente, então ele contém vetores desnecessários. Se é linearmente independente, mas não gera o espaço, então faltam direções para representar todos os vetores. Uma base é exatamente o ponto de equilíbrio entre suficiência e ausência de redundância.
Uma consequência importante é que, uma vez fixada uma base $\mathcal{B}=\{v_1,\ldots,v_n\}$, cada vetor $v\in V$ pode ser escrito de maneira única na forma
$$ v=\alpha_1v_1+\alpha_2v_2+\cdots+\alpha_nv_n $$Os escalares $\alpha_1,\ldots,\alpha_n$ são as coordenadas de $v$ nessa base. A unicidade da representação é uma das propriedades mais úteis do conceito de base, pois ela permite transformar problemas abstratos em contas com coordenadas.
Exemplo: em $\mathbb{R}^n$ temos a base canônica
$$ \vec{e}_1=(1,0,0,\ldots,0),\; \vec{e}_2=(0,1,0,\ldots,0),\; \ldots,\; \vec{e}_n=(0,0,0,\ldots,1) $$Esse conjunto é linearmente independente e gera o espaço vetorial $\mathbb{R}^n$. Por isso, qualquer vetor $(a_1,\ldots,a_n)$ pode ser escrito como
$$ (a_1,\ldots,a_n)=a_1\vec{e}_1+\cdots+a_n\vec{e}_n $$As coordenadas do vetor coincidem, nesse caso, com os próprios coeficientes da combinação linear.
Nem toda base precisa ser a base canônica. Em $\mathbb{R}^2$, por exemplo, o conjunto
$$ \mathcal{B}=\{(1,1),(1,-1)\} $$também é uma base, porque os dois vetores são linearmente independentes e geram o plano. Isso mostra que um mesmo espaço vetorial pode admitir muitas bases diferentes.
A escolha da base afeta a forma como representamos vetores e operadores, mas não altera o espaço em si. Em aplicações, escolher uma boa base pode simplificar bastante um problema. Em processamento de sinais, por exemplo, bases adequadas facilitam compressão e análise. Em álgebra linear numérica, certas bases tornam matrizes mais simples. Em aprendizado de máquina, mudanças de base podem destacar direções mais informativas nos dados.
O número de vetores em uma base finita de $V$ é sempre o mesmo. Esse número é chamado dimensão do espaço vetorial. Assim, dizer que $\mathbb{R}^3$ tem dimensão 3 significa que qualquer base de $\mathbb{R}^3$ possui exatamente 3 vetores.
Esse fato é importante porque conecta base, independência linear e geração em uma mesma noção quantitativa. Em espaços de dimensão finita, temos critérios práticos muito úteis:
- se um conjunto com $n$ vetores em um espaço de dimensão $n$ é linearmente independente, então ele já é uma base;
- se um conjunto com $n$ vetores em um espaço de dimensão $n$ gera o espaço, então ele já é uma base.
Por isso, em muitos exercícios não é necessário verificar as duas propriedades separadamente; basta usar a dimensão conhecida do espaço.
Outro ponto importante é que bases estão intimamente ligadas a mudanças de coordenadas. Se trocamos de base, o vetor geométrico continua o mesmo, mas seus coeficientes mudam. Mais adiante, essa ideia será essencial para estudar matrizes de transformações lineares, diagonalização e teorema espectral.
A soma de dois subespaços de $V$, $W_1$ e $W_2$, é dada por
$$ W_1+W_2=\{u\in V\mid u=v_1+v_2,\; v_1\in W_1,\; v_2\in W_2\} $$Essa construção é útil porque muitas decomposições de espaços vetoriais são descritas como somas de subespaços gerados por bases distintas. Quando essa decomposição é única, chegamos à noção de soma direta, discutida na próxima seção.
Sejam $W_1$ e $W_2$ subespaços do espaço vetorial $V$. Quando $W_1\cap W_2=\{\bar{0}\}$, chamamos a soma $W_1+W_2$ de soma direta e usamos a notação $W_1\oplus W_2$.
Isso significa que cada vetor de $W_1+W_2$ pode ser decomposto de maneira única como soma de um vetor de $W_1$ com um vetor de $W_2$. A unicidade é o ponto central da soma direta: não basta que o vetor pertença à soma dos subespaços; é necessário que não haja ambiguidade na decomposição.
De forma equivalente, dizer que
$$ V=W_1\oplus W_2 $$significa afirmar duas coisas ao mesmo tempo: todo vetor de $V$ pode ser escrito como $v=w_1+w_2$, com $w_1\in W_1$ e $w_2\in W_2$, e essa escrita é única.
Existe uma relação importante entre essa unicidade e a intersecção trivial. Se um vetor não nulo pertencesse tanto a $W_1$ quanto a $W_2$, então poderíamos deslocá-lo de um lado para o outro da decomposição e obter mais de uma forma de escrever o mesmo vetor. Por isso, a condição $W_1\cap W_2=\{\bar{0}\}$ é exatamente o que impede sobreposição estrutural entre os dois subespaços.
Geometricamente, em $\mathbb{R}^2$, duas retas distintas passando pela origem formam uma soma direta que gera o plano inteiro. Em $\mathbb{R}^3$, uma reta e um plano podem formar uma soma direta quando a reta não está contida no plano. Nesses casos, cada vetor do espaço pode ser decomposto de modo único em componentes associadas a cada subespaço.
Exemplo: sejam os subespaços
$$ W_1=\{(x,y,z)\in \mathbb{R}^3 \mid (x,y,z)=(2t,-t,t),\; t\in \mathbb{R} \} $$ $$ W_2=\{(x,y,z)\in \mathbb{R}^3 \mid (x,y,z)=(m,m,3m),\; m\in \mathbb{R}\} $$Determine se $W_1+W_2$ é uma soma direta.
Solução: Precisamos avaliar se a intersecção dos subespaços resulta no vetor nulo. Estamos procurando então por:$(2t,-t,t)=(m,m,3m)$ Para isso, montamos um sistema:
$$ 2t=m \\ -t=m \\ t=3m $$Das duas primeiras equações obtemos $2t=-t$, portanto $3t=0$ e então $t=0$. Consequentemente, $m=0$. Logo, o único ponto em comum é $\bar{0}$ e a soma é direta.
Uma maneira alternativa de interpretar esse resultado é notar que os vetores diretores
$$ v_1=(2,-1,1),\qquad v_2=(1,1,3) $$são linearmente independentes. Portanto, os subespaços que eles geram não se sobrepõem além do vetor nulo.
Somas diretas são especialmente importantes porque permitem decompor problemas complexos em partes independentes. Quando um espaço vetorial pode ser escrito como soma direta de subespaços mais simples, podemos estudar cada componente separadamente e depois recompor a solução total.
Essa ideia aparece com frequência em álgebra linear computacional. Por exemplo, um vetor pode ser decomposto em uma componente pertencente a um subespaço de interesse e outra pertencente a seu complemento. Projeções ortogonais, decomposições espectrais e mudanças de base muitas vezes dependem precisamente dessa separação.
Em computação, a noção de soma direta aparece em várias formas. Em processamento de sinais, um sinal pode ser decomposto em componentes pertencentes a subespaços distintos, como parte útil e ruído aproximado. Em computação gráfica, movimentos ou transformações podem ser separados em componentes independentes para facilitar cálculo e interpretação. Em aprendizado de máquina e análise de dados, decomposições em subespaços ajudam a isolar direções relevantes, reduzir dimensionalidade e separar estrutura de perturbação.
Em modelagem de sistemas dinâmicos e controle, a decomposição do espaço de estados em subespaços invariantes simplifica a análise do comportamento do sistema. Em algoritmos numéricos, decompor um espaço em partes complementares pode reduzir custo, melhorar estabilidade e tornar certas operações paralelizáveis.
Por isso, a soma direta não é apenas uma definição abstrata: ela fornece um mecanismo para organizar informação, separar componentes e estruturar soluções em contextos matemáticos e computacionais.
O objetivo da programação linear é encontrar a melhor solução possível para problemas em que tanto a função objetivo quanto as restrições podem ser modeladas por expressões lineares. Em termos geométricos, buscamos o ponto de uma região viável que maximiza ou minimiza uma função.
$$ a_1x+a_2y=b $$Quando há várias restrições desse tipo, obtemos uma região de soluções admissíveis. A solução ótima, quando existe, ocorre em um vértice dessa região. Essa é uma das propriedades geométricas fundamentais da programação linear: embora existam infinitos pontos viáveis, basta examinar pontos extremos da região definida pelas restrições.
Em um problema típico, distinguimos três componentes:
- variáveis de decisão, que representam as quantidades que queremos determinar;
- restrições, que traduzem limites de recursos, capacidade, tempo, orçamento ou compatibilidade;
- função objetivo, que mede aquilo que desejamos maximizar ou minimizar, como lucro, custo, tempo ou desperdício.
Do ponto de vista matemático, um modelo de programação linear procura resolver algo da forma
$$ \text{maximizar ou minimizar } c^T x $$ $$ \text{sujeito a } Ax\leq b,\qquad x\geq 0 $$Nessa formulação, $x$ é o vetor das variáveis de decisão, $A$ reúne os coeficientes das restrições, $b$ representa os limites disponíveis e $c$ contém os pesos da função objetivo.
O aspecto mais delicado de muitos problemas reais não é resolver o modelo, mas construí-lo corretamente. Modelar bem significa identificar quais quantidades devem virar variáveis, quais relações do problema são aproximadamente lineares e quais limitações precisam ser expressas como inequações. Um modelo mal formulado pode produzir uma solução matematicamente correta, mas inútil na prática.
Passos:
- Identificar as variáveis desconhecidas a serem determinadas - variáveis de decisão;
- Listar as restrições do problema em função das variáveis de decisão;
- Identificar o objetivo ou critério de otimização do problema - função linear com as variáveis de decisão.
Exemplo: suponha que uma fábrica de móveis fabrique dois tipos de objetos: cadeiras e mesas. Uma cadeira precisa de 5 tábuas e 10 horas de trabalho, enquanto uma mesa necessita de 20 tábuas e 15 horas de trabalho. Levando em conta que a fábrica possui 400 tábuas e 450 horas de trabalho disponíveis e que o lucro por cadeira é de $\text{R\$180,00}$ e o por mesa é de $\text{R\$320,00}$, otimize as variáveis para obter o maior lucro possível.
Nomeando a quantidade de cadeiras por $x_1$ e a quantidade de mesas por $x_2$, o modelo fica:
$$ \text{I)}\;\;5x_1+20x_2\leq 400 \quad \text{(tábuas)} $$ $$ \text{II)}\;\;10x_1+15x_2\leq 450 \quad \text{(horas)} $$ $$ \text{III)}\;\;L=180x_1+320x_2 \quad \text{(lucro)} $$Também impomos as restrições de não negatividade: $x_1\geq 0$ e $x_2\geq 0$.
Podemos começar pelo método gráfico. Para encontrar os interceptos da restrição I, analisamos dois casos:
$$ x_2=0 \Rightarrow 5x_1=400 \Rightarrow x_1=80 $$ $$ x_1=0 \Rightarrow 20x_2=400 \Rightarrow x_2=20 $$Os pontos $x_1=80$ e $x_2=20$ podem ser colocados em um gráfico bidimensional.
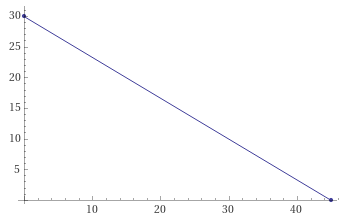
Fazendo o mesmo para a equação II), encontramos os interceptos $x_2=30$ e $x_1=45$.
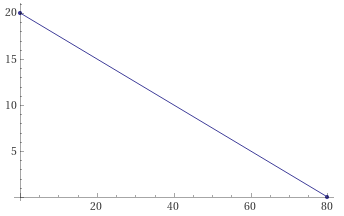
Os dois gráficos podem ser sobrepostos para obtermos a região viável do problema.
![Gráficos sobrepostos dos pontos de horas e tábuas para as restrições dadas. Fonte : Ref.: [4]](assets/img/pages/Mat_1.6_c.png)
A solução do problema está nos vértices dentro da área viável:
$$ P_1=(0,20) \\ P_2=?\\ P_3=(45,0) $$Como encontramos o ponto $P_2$? Basta resolver o sistema obtido ao transformar as restrições I e II em igualdades:
$$ 5x_1+20x_2=400\\ 10x_1+15x_2=450 $$Resolvendo, obtemos $P_2=(24,14)$.
Utilizando esses pontos na equação III), encontramos que o valor máximo de lucro:
$$ L_1=180\cdot0+320\cdot20=6400\\ L_2=180\cdot24+320\cdot14=8800\\ L_3=180\cdot45+320\cdot0=8100 $$A solução ótima é, então, produzir 24 cadeiras e 14 mesas.
Do ponto de vista analítico, avaliamos a função objetivo em todos os vértices relevantes da região viável. Como a função é linear, não é necessário testar todos os pontos internos: basta comparar os candidatos extremos.
Também é importante verificar explicitamente as restrições de não negatividade:
$$ x_1\geq 0,\qquad x_2\geq 0 $$Essas condições garantem que a solução faça sentido no contexto do problema, já que não podemos produzir quantidades negativas de cadeiras ou mesas.
Por exemplo, se tomarmos o ponto em que $x_2=0$, pela restrição I temos:
$$ 5x_1+20x_2=400\\ x_2=0\\ x_1=80 $$Mas esse ponto não é viável, pois viola a restrição II:
$$ 10\cdot80+15\cdot0=800>450 $$Esse cuidado mostra que os interceptos de cada reta, isoladamente, nem sempre pertencem à região viável final. O método gráfico e o método analítico chegam à mesma resposta quando todas as restrições são consideradas em conjunto.
O método gráfico é útil para problemas com duas variáveis, pois permite visualizar toda a região viável. No entanto, em aplicações reais, problemas de programação linear frequentemente envolvem dezenas, centenas ou milhares de variáveis. Nesses casos, a solução depende de métodos computacionais.
Dois enfoques são especialmente importantes. O primeiro é o método simplex, que percorre vértices adjacentes da região viável em busca de melhoria sucessiva da função objetivo. O segundo são os métodos de pontos interiores, que avançam pelo interior da região viável e são muito usados em implementações modernas de grande escala.
Em ambos os casos, a resolução computacional de programação linear depende fortemente de operações de álgebra linear. Sistemas lineares precisam ser resolvidos repetidamente, matrizes de restrições são fatoradas e critérios de estabilidade numérica se tornam relevantes. Por isso, programação linear e álgebra linear numérica estão intimamente ligadas.
Além da solução em si, há questões de modelagem que têm grande impacto computacional. Restrições redundantes, escalas numéricas muito diferentes entre coeficientes e matrizes excessivamente densas podem tornar a resolução mais lenta ou menos estável. Em aplicações profissionais, parte do trabalho consiste em formular modelos bem condicionados e explorar estruturas especiais, como esparsidade ou blocos repetidos.
As aplicações práticas são numerosas. Em logística, programação linear é usada para planejar transporte, estoque, distribuição e roteamento de recursos. Em manufatura, ajuda a definir mix de produção, uso de matéria-prima, escalonamento e alocação de máquinas. Em redes de computadores e telecomunicações, aparece em controle de fluxo, alocação de banda, balanceamento de carga e dimensionamento de capacidade.
Em computação, também aparece em compiladores e otimização de código, em problemas de planejamento, em inferência e ajuste de modelos, em visão computacional e em aprendizado de máquina. Certos problemas de classificação, regressão com restrições e aproximação convexa podem ser formulados ou relaxados como problemas lineares.
Em pesquisa operacional e ciência de dados, a programação linear é frequentemente o primeiro passo de modelos mais sofisticados, como programação inteira, programação convexa e otimização combinatória. Mesmo quando o problema final não é linear, versões lineares relaxadas podem fornecer limites, aproximações e heurísticas muito úteis.
Seja $T$ uma função que leva vetores de um espaço $V$ para outro $W$, isto é, $T:V\rightarrow W$. Chamamos essa função de transformação linear se:
- $T(\alpha v)=\alpha T(v), v\in V \;e\; \alpha \in \mathbb{R}$
- $T(u+v)=T(u)+T(v), \;com \;u,v\in V$
Essas propriedades mostram que a transformação preserva as operações lineares do espaço: somar vetores antes ou depois de aplicar $T$ produz o mesmo resultado, e o mesmo vale para multiplicação por escalar.
Transformações lineares são importantes porque descrevem mudanças estruturadas entre espaços vetoriais. Em vez de olhar apenas para vetores isolados, estudamos regras que transportam informação de um espaço para outro sem destruir a estrutura linear. Muitas operações centrais da matemática aplicada podem ser formuladas dessa maneira.
Em $\mathbb{R}^2$ e $\mathbb{R}^3$, exemplos clássicos de transformações lineares são rotações em torno da origem, reflexões, projeções e mudanças de escala. Todas elas preservam a origem e respeitam combinações lineares. Já uma translação simples, como $T(x,y)=(x+1,y)$, não é linear, porque não leva o vetor nulo no vetor nulo.
Um teste rápido frequentemente útil é justamente verificar se $T(0)=0$. Toda transformação linear satisfaz essa propriedade. Se uma aplicação não envia o vetor nulo para o vetor nulo, então ela não pode ser linear.
A imagem de $T$ é o conjunto $Im(T)$ dado por
$$ Im(T)=\{ w \in W \mid T(v)=w,\; \text{para algum } v \in V \} $$onde $Im(T)$ é um subespaço vetorial de $W$. A imagem representa todos os resultados que realmente podem ser produzidos por $T$.
O núcleo de $T$ é o conjunto dos vetores enviados ao vetor nulo:
$$ ker(T)=\{v\in V\mid T(v)=\bar{0} \} $$O núcleo também é um subespaço vetorial de $V$. Ele mede, em certo sentido, quanta informação se perde ao aplicar a transformação. Se o núcleo contém apenas o vetor nulo, então vetores diferentes não colapsam no mesmo resultado e a transformação é injetiva.
Quando fixamos bases para $V$ e $W$, toda transformação linear pode ser representada por uma matriz. Assim, estudar transformações lineares e estudar matrizes são duas faces do mesmo problema.
Se $V=\mathbb{R}^n$ e $W=\mathbb{R}^m$, toda transformação linear pode ser escrita na forma
$$ T(x)=Ax $$em que $A$ é uma matriz $m\times n$. Cada coluna de $A$ mostra a imagem de um vetor da base canônica de $\mathbb{R}^n$. Isso significa que conhecer a ação de $T$ sobre os vetores básicos já determina completamente a transformação.
Por exemplo, considere a transformação $T:\mathbb{R}^2\rightarrow\mathbb{R}^2$ dada por
$$ T(x,y)=(2x+y,x-y) $$Ela pode ser representada pela matriz
$$ A= \begin{bmatrix} 2 & 1 \\ 1 & -1 \end{bmatrix} $$pois
$$ A \begin{bmatrix} x\\ y \end{bmatrix} = \begin{bmatrix} 2x+y\\ x-y \end{bmatrix} $$Esse tipo de representação torna a composição de transformações especialmente simples. Se $T_1$ e $T_2$ são transformações lineares representadas por matrizes $A$ e $B$, então a composição corresponde ao produto matricial. Isso conecta diretamente propriedades algébricas das matrizes com o efeito geométrico ou computacional das transformações.
Teorema do núcleo e da imagem: se $V$ e $W$ são espaços vetoriais de dimensão finita e $T:V\rightarrow W$ é uma transformação linear, então
$$ dim(V)=dim(ker(T))+dim(Im(T)) $$Esse resultado também é conhecido como teorema do posto e da nulidade. Ele diz que a dimensão do espaço de partida se divide entre a parte que desaparece no núcleo e a parte efetivamente preservada na imagem.
Na prática, transformações lineares aparecem em muitos contextos computacionais. Em computação gráfica, são usadas para rotação, escala, reflexão, mudança de coordenadas, projeção de cenas e composição de movimentos. Em processamento de imagens, filtros lineares e convoluções discretizadas podem ser descritos por operadores lineares. Em processamento de sinais, transformadas como Fourier e wavelets são estudadas como transformações lineares entre representações diferentes do mesmo dado.
Em aprendizado de máquina, multiplicações por matrizes aparecem o tempo todo: camadas lineares, projeções em subespaços, redução de dimensionalidade, PCA e transformações de atributos dependem diretamente desse formalismo. Em grafos e redes, matrizes de adjacência e operadores associados transformam vetores de estados e permitem estudar propagação, centralidade e dinâmica em redes.
Em algoritmos numéricos, transformar vetores por matrizes é uma operação básica, e compreender a imagem, o núcleo, a composição e a invertibilidade de transformações lineares ajuda a prever custo computacional, perda de informação e estabilidade.
Seja $T:V\rightarrow V$ uma transformação linear. Dizemos que o escalar $\lambda$ é um autovalor de $T$ se existir um vetor não nulo $v\in V$ tal que
$$ T(v)=\lambda v $$Dizemos que esse vetor $v$ é o autovetor de $T$ associado ao autovalor $\lambda$.
Intuitivamente, autovetores são direções preservadas pela transformação: o vetor pode ser alongado, comprimido ou invertido de sentido, mas continua sobre a mesma reta gerada por ele. O autovalor associado informa a intensidade e o tipo dessa alteração. Se $\lambda>1$, ocorre expansão; se $0<\lambda<1$, ocorre contração; se $\lambda<0$, além da mudança de escala há inversão de sentido; e se $\lambda=0$, o autovetor é enviado ao vetor nulo.
Esse conceito é especialmente importante porque permite identificar direções privilegiadas de uma transformação linear. Mesmo quando a transformação é complicada no espaço inteiro, ela pode se comportar de forma muito simples sobre certos vetores especiais.
Se $A$ é a matriz associada a $T$, então procurar autovetores e autovalores equivale a resolver
$$ Av=\lambda v $$ou, de forma equivalente,
$$ (A-\lambda I)v=0 $$Como estamos procurando soluções não nulas para $v$, esse sistema homogêneo só pode ter solução não trivial quando a matriz $A-\lambda I$ não é invertível.
Polinômio característico: seja $A$ a matriz associada ao operador linear $T: V\rightarrow V$ em relação a uma base $B$, os autovalores de $T$ são as soluções da equação:
$$ det(A-\lambda I)=0 $$O polinômio característico é dado por $p(\lambda)=det(A-\lambda I)$.
Depois de encontrar um autovalor $\lambda$, os autovetores associados a ele são obtidos resolvendo o sistema homogêneo
$$ (A-\lambda I)v=0 $$O conjunto de todas as soluções desse sistema, junto com o vetor nulo, forma o autoespaço associado a $\lambda$.
Exemplo: considere a matriz
$$ A= \begin{bmatrix} 3 & 0 \\ 0 & 2 \end{bmatrix} $$Nesse caso, os vetores da forma $(x,0)$ são autovetores associados a $\lambda=3$, e os vetores da forma $(0,y)$ são autovetores associados a $\lambda=2$. A transformação preserva exatamente as direções dos eixos coordenados.
Em uma matriz diagonal, os autovalores aparecem diretamente na diagonal. Em matrizes mais gerais, o cálculo pode ser mais trabalhoso, mas a interpretação continua a mesma: estamos procurando direções cujas imagens não saem da reta gerada pelo vetor original.
O estudo de autovalores também está ligado ao comportamento iterado de transformações. Se aplicamos repetidamente uma matriz $A$ a um vetor, isto é, se observamos $A^k v$, as direções associadas aos maiores autovalores em módulo tendem a dominar o comportamento assintótico do sistema. Esse fato é central em dinâmica linear, métodos iterativos e análise de estabilidade.
Polinômio minimal: seja $A$ uma matriz quadrada sobre $\mathbb{R}$ e $J(A)$, não vazio, o conjunto de todos os polinômios $f(t)$ tais que $f(A)=0$. Se $m(t)$ é o polinômio mônico de menor grau em $J(A)$, então ele é chamado polinômio minimal de $A$ e é único.
O polinômio minimal divide o polinômio característico e fornece informação importante sobre diagonalização e formas canônicas. Para encontrá-lo, podemos seguir os passos:
- Achar o polinômio característico $p(\lambda)$;
- Calcular as raízes de $p(\lambda)$;
- Encontrar polinômios $m_i(t)$ que dividem $p(\lambda);$
- Calcular $m_i(A)$ e encontrar aquele em que $m_j(A)=0.$
Autovalores e autovetores têm aplicações práticas muito amplas. Em análise de dados, aparecem em PCA, onde autovetores da matriz de covariância determinam direções principais de variação. Em grafos e redes, autovalores e autovetores de matrizes de adjacência ou Laplacianas ajudam a estudar conectividade, centralidade e particionamento.
Em processamento de sinais e imagens, transformações ortogonais e espectrais usam bases de autovetores para separar componentes mais relevantes do sinal. Em sistemas dinâmicos e controle, os autovalores de uma matriz de transição ajudam a determinar estabilidade, crescimento, amortecimento e oscilação de estados.
Em algoritmos numéricos e aprendizado de máquina, métodos iterativos como power iteration e variantes associadas exploram diretamente o comportamento espectral de matrizes para encontrar autovalores dominantes e direções principais. Essas técnicas são importantes em recomendação, ranking, compressão e análise de estruturas de grande escala.
Seja $T:V\rightarrow V$ um operador linear com $B=\{v_1,v_2,\ldots,v_n \}$ uma base de $V$. Se cada $v_i$ for um autovetor de $T$ associado a um autovalor $\lambda_i$, então a matriz de $T$ nessa base é diagonal, isto é,
$$ P^{-1}AP=D $$onde $P$ é a matriz cujas colunas são os vetores $v_i$, $A$ é a matriz de $T$ na base original e $D$ é a matriz diagonal com $[D]_{ii}=\lambda_i$.
Diagonalizar uma matriz significa encontrar uma base em que a transformação associada tenha a forma mais simples possível: em vez de misturar coordenadas, ela apenas multiplica cada direção básica por um escalar. Em termos conceituais, isso equivale a descrever o operador em coordenadas alinhadas com seus autovetores.
Uma matriz é diagonalizável quando existe uma base formada inteiramente por autovetores. Isso ocorre, por exemplo, quando ela possui $n$ autovetores linearmente independentes. Nesse caso, a matriz $P$ é invertível e a transformação de coordenadas dada por $P^{-1}AP$ revela a estrutura espectral de $A$.
Uma condição suficiente bastante comum é a existência de $n$ autovalores distintos. Nesse caso, os autovetores associados são linearmente independentes, o que garante diagonalização. No entanto, uma matriz ainda pode ser diagonalizável mesmo com autovalores repetidos, desde que a dimensão dos autoespaços seja suficiente para formar uma base completa.
Essa distinção está ligada a duas noções importantes: multiplicidade algébrica e multiplicidade geométrica. A multiplicidade algébrica de um autovalor é o número de vezes que ele aparece como raiz do polinômio característico. Já a multiplicidade geométrica é a dimensão do autoespaço correspondente. Para que a diagonalização seja possível, é necessário que os autoespaços forneçam vetores independentes em quantidade suficiente.
Quando isso não acontece, a matriz não pode ser diagonalizada, embora ainda possa ser estudada por formas canônicas mais gerais, como a forma de Jordan. Esse caso aparece quando há autovalores repetidos, mas poucos autovetores independentes.
Um exemplo simples de matriz diagonalizável é
$$ A= \begin{bmatrix} 4 & 0 \\ 0 & 1 \end{bmatrix} $$Nesse caso, a matriz já está diagonal e seus autovetores são os vetores da base canônica. Um exemplo menos trivial é uma matriz não diagonal que admite mudança de base para uma forma diagonal. O ganho está justamente em substituir uma representação mais difícil por outra em que o operador atua coordenada a coordenada.
A principal utilidade prática da diagonalização é simplificar cálculos com potências de matrizes. Se
$$ A=PDP^{-1}, $$então
$$ A^k=PD^kP^{-1} $$e elevar $D$ a uma potência é muito simples, pois basta elevar cada elemento diagonal:
$$ D^k= \begin{bmatrix} \lambda_1^k & 0 & \cdots & 0 \\ 0 & \lambda_2^k & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_n^k \end{bmatrix} $$Isso é extremamente útil no estudo de recorrências lineares, cadeias de transformação, processos iterativos e sistemas dinâmicos discretos, nos quais aparecem expressões como $A^k x_0$.
Em computação, diagonalização e decomposições espectrais aparecem em muitas aplicações. Em modelagem de sistemas, ajudam a entender modos de crescimento, decaimento e oscilação. Em análise de redes e grafos, autovalores e autovetores organizam a estrutura de conectividade. Em ciência de dados, técnicas como PCA dependem da decomposição espectral de matrizes simétricas para identificar direções principais de variação.
Em algoritmos numéricos, a diagonalização também tem valor interpretativo: mesmo quando não calculamos explicitamente $P$ e $D$, pensar em termos espectrais ajuda a analisar convergência de métodos iterativos, estabilidade de operadores e comportamento assintótico de transformações repetidas.
Seja $V$ um espaço vetorial sobre o corpo dos reais. Chamamos de produto interno uma função que associa cada par de vetor $u,v$ em $V$ com um número real denotado por $\langle u,v \rangle $, tal que
- $\langle u,u\rangle\geq 0,$ para todo $u\in V$
- $\langle u,u\rangle=0,$se e somente se $u=\bar{0}$
- $\langle u_1+u_2,v\rangle=\langle u_1,v\rangle+\langle u_2,v\rangle$
- $\langle\alpha u,v\rangle=\alpha\langle u,v \rangle$
- $\langle u,v\rangle=\langle v,u\rangle$
Essas propriedades transformam o espaço vetorial em um ambiente onde, além de somar e escalar vetores, também podemos medir comprimento, distância, ângulo e ortogonalidade. O produto interno introduz, portanto, uma estrutura geométrica sobre o espaço.
O exemplo mais familiar é o produto escalar usual em $\mathbb{R}^n$:
$$ \langle u,v\rangle=u_1v_1+u_2v_2+\cdots+u_nv_n $$Quando usamos esse produto interno, recuperamos a geometria euclidiana habitual. No entanto, outros produtos internos podem ser definidos e são úteis em aplicações específicas, desde que satisfaçam os axiomas acima.
O produto interno permite definir comprimento e ângulo. A norma de um vetor é dada por
$$ ||u||=\sqrt{\langle u,u\rangle} $$e dois vetores são ortogonais quando $\langle u,v\rangle=0$.
Exemplo: em $\mathbb{R}^2$, tomando $u=(1,2)$ e $v=(2,-1)$, temos
$$ \langle u,v\rangle=1\cdot 2+2\cdot(-1)=0 $$Logo, os vetores são ortogonais. Além disso,
$$ ||u||=\sqrt{1^2+2^2}=\sqrt{5},\qquad ||v||=\sqrt{2^2+(-1)^2}=\sqrt{5} $$Esse exemplo mostra que vetores podem ter o mesmo comprimento e ainda apontar em direções perpendiculares.
Com a norma, podemos definir distância entre vetores por
$$ d(u,v)=||u-v|| $$Essa noção é essencial porque permite medir proximidade entre objetos representados vetorialmente, como pontos, sinais, documentos, imagens ou amostras de dados.
Outra relação fundamental é a desigualdade de Cauchy-Schwarz:
$$ |\langle u,v\rangle|\leq ||u||\;||v|| $$Ela garante, entre outras coisas, que a expressão do cosseno do ângulo entre dois vetores faz sentido:
$$ \cos\theta=\frac{\langle u,v\rangle}{||u||\;||v||} $$Assim, o produto interno não apenas mede alinhamento entre vetores, mas também quantifica similaridade direcional.
Esse ponto de vista é muito importante em computação. Em recuperação de informação, sistemas de recomendação e busca semântica, a similaridade entre vetores é frequentemente avaliada por meio do cosseno do ângulo entre eles. Em embeddings de palavras, documentos ou imagens, vetores com ângulo pequeno tendem a representar objetos semanticamente parecidos.
O produto interno também está por trás das projeções ortogonais. Quando queremos aproximar um vetor por outro pertencente a um subespaço, a condição de melhor aproximação é expressa em termos de ortogonalidade do erro residual. Essa ideia aparece em mínimos quadrados, compressão, filtragem, reconstrução de sinais e métodos de otimização.
Em espaços de funções, produtos internos permitem comparar funções de maneira análoga à comparação entre vetores em $\mathbb{R}^n$. Isso é importante em séries de Fourier, métodos numéricos para equações diferenciais e aproximação funcional.
Em aprendizado de máquina, muitos algoritmos dependem direta ou indiretamente de produto interno. Regressão linear, classificadores lineares, PCA, métodos de kernel e vários algoritmos de otimização usam produtos internos para medir alinhamento entre dados, parâmetros e gradientes. Em álgebra linear numérica, ortogonalidade e norma são cruciais para estabilidade computacional, especialmente em fatorações e métodos iterativos.
Seja $\mathcal{B}$ uma base ortogonal de $\mathbb{R}^n$. Então, qualquer vetor $\vec{v}\in \mathbb{R}^n$ pode ser representado como
$$ \vec{v}=\frac{\vec{v}\cdot\vec{v_1}}{\vec{v_1}\cdot\vec{v_1}} \vec{v_1}+\frac{\vec{v}\cdot\vec{v_2}}{\vec{v_2}\cdot\vec{v_2}} \vec{v_2}+\cdots+\frac{\vec{v}\cdot\vec{v_n}}{\vec{v_n}\cdot\vec{v_n}} \vec{v_n} $$ou, de outra maneira, como soma de projeções ortogonais:
$$ \vec{v}=proj_{\vec{v_1}}\vec{v}+proj_{\vec{v_2}}\vec{v}+\cdots+proj_{\vec{v_n}}\vec{v} $$onde $proj_{\vec{v_i}}=c_i=\frac{\vec{v}\cdot\vec{v_i}}{\vec{v_i}\cdot\vec{v_i}}$ e temos os coeficientes para gerar o vetor $\vec{v}$.
Se a base for ortonormal, então $\vec{v_i}\cdot\vec{v_i}=1$ e os coeficientes ficam ainda mais simples: $c_i=\vec{v}\cdot\vec{v_i}$.
Para que vetores ortogonais sejam ortonormais, basta normalizá-los:
$$ \widehat{u}=\frac{\vec{u}}{||\vec{u}||} $$Assim, uma base ortonormal é um conjunto de vetores ${\vec{v_1},\vec{v_2},\ldots,\vec{v_n}}$ tal que $||\vec{v_i}||=1$ para todo $i$ e $\vec{v_i}\cdot\vec{v_j}=0$ quando $i\neq j$.
Exemplo: os vetores
$$ e_1=\left(\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}}\right),\qquad e_2=\left(\frac{1}{\sqrt{2}},-\frac{1}{\sqrt{2}}\right) $$formam uma base ortonormal de $\mathbb{R}^2$, pois ambos têm norma 1 e
$$ e_1\cdot e_2=\frac{1}{2}-\frac{1}{2}=0 $$Se $v=(3,1)$, então suas coordenadas nessa base são
$$ c_1=v\cdot e_1=\frac{4}{\sqrt{2}}=2\sqrt{2},\qquad c_2=v\cdot e_2=\frac{2}{\sqrt{2}}=\sqrt{2} $$e, portanto,
$$ v=2\sqrt{2}\,e_1+\sqrt{2}\,e_2 $$Bases ortonormais são especialmente valiosas porque simplificam drasticamente os cálculos. Em uma base qualquer, determinar coordenadas pode exigir resolver sistemas lineares. Em uma base ortonormal, as coordenadas são obtidas diretamente por produtos internos. Isso reduz custo algébrico e melhora estabilidade numérica.
O procedimento padrão para construir bases ortonormais a partir de vetores linearmente independentes é o processo de Gram-Schmidt. A ideia é transformar uma base qualquer em outra base com os mesmos vetores geradores, mas ortogonais entre si, e depois normalizá-los.
Se começamos com vetores linearmente independentes $u_1,u_2,\ldots,u_n$, o processo produz vetores ortogonais $w_1,w_2,\ldots,w_n$ removendo de cada vetor suas componentes nas direções anteriores. Em seguida, normalizamos cada $w_i$ para obter uma base ortonormal.
Por exemplo, se começamos com $u_1=(1,1)$ e $u_2=(1,0)$, então
$$ w_1=u_1=(1,1) $$ $$ w_2=u_2-\frac{u_2\cdot w_1}{w_1\cdot w_1}w_1 =(1,0)-\frac{1}{2}(1,1)=\left(\frac{1}{2},-\frac{1}{2}\right) $$Depois normalizamos $w_1$ e $w_2$ para obter uma base ortonormal.
Esse procedimento tem aplicações importantes em computação científica. Ele aparece em decomposições matriciais, como a fatoração QR, muito usada para resolver sistemas lineares, problemas de mínimos quadrados e cálculo numérico de autovalores.
Em processamento de sinais, bases ortonormais permitem decompor sinais em componentes independentes sem misturar energia entre coordenadas. Em computação gráfica e simulação, referenciais ortonormais facilitam rotação, projeção, iluminação e controle de câmera. Em aprendizado de máquina e análise de dados, representar informação em bases ortonormais ajuda a interpretar variância, decorrelação e compressão.
A projeção ortogonal de um vetor $\vec{y}$ na direção de $\vec{w}$ é dada por
$$ \vec{k}=proj_{\vec{w}}\vec{y}=\frac{\vec{y}\cdot\vec{w}}{\vec{w}\cdot\vec{w}}\vec{w} $$A projeção ortogonal de um vetor $\vec{y}$ em um subespaço $F$ gerado por vetores ortogonais $\vec{w_1},\vec{w_2}$ é dada por:
$$ \vec{k}=proj_F\vec{y}=proj_{\vec{w_1}}\vec{y}+proj_{\vec{w_2}}\vec{y}= \frac{\vec{y}\cdot\vec{w_1}}{\vec{w_1}\cdot\vec{w_1}}\vec{w_1}+\frac{\vec{y}\cdot\vec{w_2}}{\vec{w_2}\cdot\vec{w_2}}\vec{w_2} $$O vetor residual
$$ \vec{r}=\vec{y}-\vec{k} $$é ortogonal ao subespaço $F$. Essa decomposição, $\vec{y}=\vec{k}+\vec{r}$, separa o vetor em uma componente explicada pelo subespaço e outra componente perpendicular a ele.
Exemplo: se $\vec{y}=(3,1)$ e $\vec{w}=(1,1)$, então
$$ proj_{\vec{w}}\vec{y} =\frac{(3,1)\cdot(1,1)}{(1,1)\cdot(1,1)}(1,1) =\frac{4}{2}(1,1)=(2,2) $$O residual é
$$ \vec{r}=(3,1)-(2,2)=(1,-1) $$e de fato $\vec{r}\cdot \vec{w}=1\cdot 1+(-1)\cdot 1=0$.
Geometricamente, a projeção ortogonal é o ponto do subespaço mais próximo do vetor original. Esse fato torna projeções fundamentais em problemas de aproximação: quando queremos substituir um objeto complicado por outro mais simples dentro de uma classe restrita, a melhor escolha costuma ser uma projeção.
Se a base do subespaço não for ortogonal, ainda podemos projetar, mas o cálculo deixa de ser uma simples soma de projeções individuais e normalmente envolve resolver um sistema linear. É por isso que bases ortonormais são tão convenientes.
Em computação, projeções aparecem em muitas tarefas. Em gráficos 3D, projetamos pontos do espaço sobre um plano de visualização. Em aprendizado de máquina, projetamos dados em subespaços de menor dimensão para reduzir custo e ruído. Em compressão e filtragem, aproximamos sinais por combinações de poucos vetores de base. Em mínimos quadrados, a solução ajustada é obtida exatamente como projeção do vetor observado sobre o espaço coluna da matriz do modelo.
Em análise numérica e métodos iterativos, projetar vetores sobre subespaços também é uma estratégia central para construir aproximações sucessivas cada vez melhores.
Movimentos rígidos são transformações geométricas que preservam distâncias e ângulos. Em outras palavras, a figura muda de posição ou orientação, mas não de tamanho nem de forma.
No plano, há três tipos básicos de movimentos rígidos: translações, reflexões e rotações em torno de um ponto. No espaço, a reflexão é relativa a um plano e a rotação é dada em torno de um eixo orientado.
Essas transformações podem ser descritas por matrizes ortogonais, eventualmente combinadas com vetores de translação. Quando a origem permanece fixa, a parte linear do movimento rígido é representada por uma matriz ortogonal, isto é, uma matriz $Q$ que satisfaz $Q^TQ=I$.
Exemplo: a rotação de ângulo $\theta$ no plano é dada por
$$ R_\theta= \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} $$Essa matriz preserva comprimentos porque $R_\theta^TR_\theta=I$. Se $\theta=\frac{\pi}{2}$, então
$$ R_{\pi/2}= \begin{bmatrix} 0 & -1\\ 1 & 0 \end{bmatrix} $$e o vetor $(1,0)$ é enviado em $(0,1)$.
O teorema de Euler afirma que todo movimento rígido, no plano ou no espaço, pode ser obtido por uma composição de translações, rotações e reflexões, conforme o caso.
Movimentos rígidos são essenciais em computação gráfica, robótica, visão computacional, realidade virtual e modelagem geométrica. Em gráficos 3D, eles permitem posicionar objetos sem deformá-los. Em robótica, descrevem movimento de braços mecânicos, sensores e câmeras. Em visão computacional, ajudam a relacionar diferentes pontos de vista de uma mesma cena.
Quando trabalhamos com coordenadas homogêneas, é comum representar a parte linear e a translação em uma única matriz ampliada. Isso torna composição e implementação computacional mais diretas, especialmente em pipelines gráficos.
O método dos mínimos quadrados é útil para resolver sistemas em que não existe solução exata, isto é, quando o sistema é incompatível. Em vez de satisfazer exatamente todas as equações, buscamos a solução que minimiza o erro total entre $A\vec{x}$ e $\vec{b}$.
$$ A\vec{x}=\vec{b} $$Geometricamente, isso equivale a projetar o vetor $\vec{b}$ sobre o espaço coluna de $A$. O vetor aproximado $A\widehat{x}$ é o ponto desse subespaço mais próximo de $\vec{b}$.
Para obter essa aproximação, construímos o sistema normal:
$$ A^TA\vec{x}=A^T\vec{b} $$Resolvendo esse novo sistema, encontramos a solução de mínimos quadrados. O vetor residual
$$ r=\vec{b}-A\widehat{x} $$fica ortogonal ao espaço coluna de $A$, o que caracteriza a melhor aproximação possível dentro do modelo linear escolhido.
Exemplo: considere o sistema incompatível
$$ \begin{cases} x=1\\ x=2 \end{cases} $$Ele pode ser escrito como
$$ A= \begin{bmatrix} 1\\ 1 \end{bmatrix}, \qquad \vec{b}= \begin{bmatrix} 1\\ 2 \end{bmatrix} $$As equações normais ficam
$$ A^TAx=A^T\vec{b} \Rightarrow [2]x=[3] \Rightarrow x=\frac{3}{2} $$Portanto, a melhor solução no sentido dos mínimos quadrados é $x=1{,}5$.
Na prática, esse método aparece em ajuste de curvas, regressão linear, calibração de sensores, reconstrução de sinais, visão computacional e tratamento de dados experimentais. Em ciência de dados, ele está na base de muitos modelos de previsão e inferência.
Em implementação numérica, costuma-se evitar a resolução direta das equações normais quando possível, porque isso pode amplificar erros de arredondamento. Métodos baseados em fatoração QR ou decomposição em valores singulares frequentemente são preferidos em problemas mais sensíveis.
Em espaços com produto interno, muitas transformações lineares podem ser estudadas por meio de sua interação com comprimentos, ângulos e projeções. Um conceito importante nesse contexto é o de funcional linear.
Seja $V$ um espaço vetorial. Definimos um funcional linear como
$$ \Phi:V\rightarrow \mathbb{R} $$onde
- $\Phi(v+w)=\Phi(v)+\Phi(w), \forall v,w\in V$
- $\Phi(\lambda v)=\lambda\Phi(v), \forall v\in V$
Ou seja, um funcional linear transforma vetores em números reais sem perder a estrutura linear. Em espaços com produto interno, esses funcionais podem ser representados de maneira particularmente elegante.
Essa classe de aplicações é importante porque mede aspectos escalares de vetores: extração de coordenadas, avaliação de alinhamento, resposta de sensores lineares e projeção sobre direções de interesse podem ser descritas por funcionais lineares.
Em computação e processamento de dados, funcionais lineares aparecem o tempo todo. O cálculo de uma média ponderada, a ativação linear de um neurônio sem não linearidade, a leitura de um canal de sensor ou a projeção de dados sobre um atributo específico são exemplos desse tipo de transformação.
O conjunto de todos os funcionais lineares é chamado de espaço dual:
$$ V^*=\{\Phi:V\rightarrow \mathbb{R}\;|\;\Phi\; \text{é funcional \; linear\}} $$O espaço dual também é um espaço vetorial.
O teorema de representação para funcionais lineares afirma que, em espaços com produto interno de dimensão finita, dado um $\Phi\in V^*$, existe um único $v\in V$ tal que
$$ \Phi(w)=\langle v,w \rangle \;, \forall \; w\in V $$Esse resultado mostra que todo funcional linear pode ser visto como um produto interno com um vetor fixo. Ele cria uma ponte importante entre vetores e funcionais.
Exemplo: em $\mathbb{R}^2$, considere o funcional
$$ \Phi(x,y)=3x-2y $$Ele pode ser escrito como
$$ \Phi(x,y)=\left\langle (3,-2),(x,y)\right\rangle $$Logo, o vetor que representa esse funcional no produto interno usual é $(3,-2)$.
Isso significa que medir linearmente um vetor é, em essência, compará-lo com uma direção fixa do espaço. Em termos computacionais, muitas operações lineares sobre dados podem ser interpretadas como produto interno com um vetor de pesos.
Esse ponto de vista é central em regressão linear, classificação linear, embeddings e filtros digitais. Quando um modelo computa uma pontuação como soma ponderada de atributos, ele está realizando exatamente esse tipo de operação.
Seja $V$ um espaço vetorial com produto interno. O operador adjunto, $T^*:V\rightarrow V$, de um operador linear $T$ em $V$, é definido por
$$ \langle T(u),v \rangle=\langle u,T^*(v) \rangle \;, \forall \;u,v\in V $$Todo operador linear possui um único operador adjunto. Esse conceito generaliza a transposta de uma matriz: em bases ortonormais reais, a matriz de $T^*$ coincide com a transposta da matriz de $T$.
Exemplo: se
$$ A= \begin{bmatrix} 1 & 2\\ 0 & 3 \end{bmatrix}, $$então, no produto interno usual em $\mathbb{R}^2$, o adjunto é representado por
$$ A^T= \begin{bmatrix} 1 & 0\\ 2 & 3 \end{bmatrix} $$Isso pode ser verificado diretamente comparando $\langle Au,v\rangle$ com $\langle u,A^Tv\rangle$.
O adjunto permite transferir a ação de uma transformação de um lado do produto interno para o outro, preservando a comparação geométrica entre vetores. Isso é muito útil quando queremos entender simetria, ortogonalidade, conservação de energia e comportamento espectral de operadores.
Em computação numérica, o adjunto aparece em algoritmos de otimização, retropropagação, problemas inversos e métodos iterativos. Em muitos desses contextos, a operação “voltar” uma informação através de um operador linear é modelada justamente pelo adjunto.
Dado um espaço vetorial $V$ e uma transformação linear $T$, temos:
Operador simétrico ou auto-adjunto: $\langle T(u),v\rangle=\langle u,T(v)\rangle$. Em bases ortonormais reais, isso corresponde a matrizes simétricas.
Operador ortogonal: $T^*=T^{-1}$. Esse tipo de operador preserva produto interno, norma e ângulos. Em espaços complexos, o análogo é chamado operador unitário.
Operador normal: $T^*T=TT^*$. Todo operador auto-adjunto e todo operador ortogonal ou unitário é normal.
Essas classes são importantes porque possuem propriedades espectrais mais fortes e, em muitos casos, admitem bases ortonormais de autovetores.
Exemplo de matriz simétrica:
$$ \begin{bmatrix} 2 & 1\\ 1 & 2 \end{bmatrix} $$Exemplo de matriz ortogonal:
$$ \begin{bmatrix} 0 & -1\\ 1 & 0 \end{bmatrix} $$Nesse segundo caso, a transposta coincide com a inversa, e a transformação preserva comprimentos.
Operadores auto-adjuntos modelam situações em que a transformação está alinhada com a geometria do espaço e costuma produzir autovalores reais. Operadores ortogonais ou unitários preservam integralmente a estrutura geométrica, sendo naturais em rotações, mudanças de fase e transformações que não deformam energia ou comprimento.
Em computação gráfica, operadores ortogonais descrevem rotações e reflexões. Em processamento de sinais, operadores unitários aparecem em transformadas que preservam energia. Em mecânica quântica e modelagem espectral, operadores auto-adjuntos e normais são centrais justamente por causa de suas propriedades espectrais bem comportadas.
Seja $A\in M_{n\times n}(\mathbb{R})$ simétrica. Então $A$ é diagonalizável sobre os reais. Existe uma matriz ortogonal $P$ tal que
$$ A=P\cdot D\cdot P^{-1}, \; P^{-1}=P^T $$Como $P^{-1}=P^T$, a diagonalização pode ser escrita como $A=PDP^T$. Isso significa que a matriz é diagonalizável por uma mudança de base ortonormal.
No $\mathbb{R}^n$, se $\mathcal{A}$ e $\mathcal{B}$ são bases, a matriz de mudança de base é ortogonal se e somente se $\mathcal{B}$ é ortonormal. Assim, existe uma base ortonormal $\mathcal{B}$ de autovetores de $A$, tal que
$$ Av_i=\lambda_i v_i,\qquad i=1,\ldots,n $$Esse resultado é central porque combina diagonalização com ortogonalidade, simplificando problemas de geometria, otimização e equações diferenciais.
Exemplo: a matriz
$$ A= \begin{bmatrix} 2 & 1\\ 1 & 2 \end{bmatrix} $$é simétrica. Seus autovalores são $3$ e $1$, com autovetores associados, por exemplo, $(1,1)$ e $(1,-1)$. Após normalização, obtemos uma base ortonormal de autovetores, o que ilustra concretamente o teorema espectral.
O teorema espectral é especialmente poderoso porque garante não apenas a existência de autovetores suficientes, mas também a possibilidade de escolhê-los ortonormais. Isso torna a decomposição numericamente mais estável e geometricamente mais interpretável.
Em análise de dados, isso aparece diretamente em PCA, onde matrizes simétricas como a matriz de covariância são decompostas em autovalores e autovetores ortogonais. Em física e engenharia, o resultado ajuda a separar modos independentes de vibração, energia e propagação.
Em algoritmos, o teorema espectral permite tratar certos operadores como combinações independentes de modos simples, o que facilita compressão, filtragem, análise modal, redução de dimensionalidade e solução de problemas quadráticos.
Formas canônicas são representações padronizadas de matrizes que preservam a estrutura essencial do operador linear, mas facilitam sua análise.
A forma canônica de Jordan representa uma matriz por blocos de Jordan associados aos autovalores. Em geral, esses blocos aparecem em uma matriz triangular superior, e a forma de Jordan é especialmente útil quando a matriz não é diagonalizável.
Essa forma permite entender melhor multiplicidades algébricas e geométricas, cadeias de autovetores generalizados e o comportamento de potências e exponenciais de matrizes.
Exemplo: a matriz
$$ J= \begin{bmatrix} 2 & 1\\ 0 & 2 \end{bmatrix} $$já está em forma de Jordan. Ela possui autovalor 2 com multiplicidade algébrica 2, mas não possui dois autovetores linearmente independentes. Por isso, não é diagonalizável.
Em termos práticos, formas canônicas servem para reduzir o problema de estudar uma matriz arbitrária ao estudo de uma forma normal mais simples e padronizada. Isso facilita comparação entre operadores, classificação estrutural e análise de estabilidade.
Mesmo quando a diagonalização falha, a forma de Jordan ainda revela quão longe a matriz está de ser diagonalizável. Os blocos de Jordan mostram onde faltam autovetores independentes e como a transformação mistura direções que compartilham o mesmo autovalor.
Em sistemas dinâmicos, controle, solução de equações diferenciais lineares e análise simbólica, formas canônicas ajudam a prever comportamento iterado, calcular exponenciais de matrizes e descrever modos acoplados. Em computação algébrica, também fornecem uma linguagem útil para classificação e simplificação de operadores lineares.
Glossário
- Autoespaço
- Subespaço formado por todos os autovetores associados a um mesmo autovalor, junto com o vetor nulo.
- Autovalor
- Escalar $\lambda$ tal que existe vetor não nulo $v$ com $Av=\lambda v$.
- Autovetor
- Vetor não nulo cuja direção é preservada por uma transformação linear.
- Base canônica
- Base padrão de $\mathbb{R}^n$, formada por vetores com um único 1 e os demais componentes iguais a 0.
- Base ortonormal
- Base cujos vetores têm norma 1 e são ortogonais entre si.
- Bloco de Jordan
- Bloco matricial usado na forma de Jordan para representar autovalores e acoplamentos entre autovetores generalizados.
- Cadeia de autovetores generalizados
- Sequência de vetores usada quando uma matriz não tem autovetores suficientes para ser diagonalizada.
- Covariância
- Medida de variação conjunta entre variáveis; sua matriz é muito usada em análise de dados e PCA.
- Decomposição espectral
- Representação de um operador ou matriz em termos de seus autovalores e autovetores.
- Dimensão
- Número de vetores de qualquer base de um espaço vetorial finito.
- Embedding
- Representação vetorial de objetos como palavras, imagens ou documentos em um espaço de dimensão finita.
- Espaço coluna
- Subespaço gerado pelas colunas de uma matriz.
- Espaço dual
- Conjunto de todos os funcionais lineares de um espaço vetorial.
- Fatoração LU
- Decomposição de uma matriz em produto de uma matriz triangular inferior por uma matriz triangular superior.
- Fatoração QR
- Decomposição de uma matriz em produto de uma matriz ortogonal por uma matriz triangular.
- Funcional linear
- Aplicação linear que associa vetores a números reais.
- Gradientes conjugados
- Método iterativo para resolver certos sistemas lineares grandes, especialmente esparsos e simétricos.
- Gram-Schmidt
- Procedimento que transforma vetores linearmente independentes em uma base ortogonal ou ortonormal.
- Imagem de uma transformação
- Conjunto de todos os vetores que podem ser obtidos como saída da transformação.
- Kernel
- Veja núcleo.
- Laplaciana de um grafo
- Matriz associada a um grafo usada para estudar conectividade, difusão e particionamento.
- Matriz esparsa
- Matriz com muitos elementos nulos, comum em problemas computacionais de grande escala.
- Matriz de adjacência
- Matriz que registra as conexões entre vértices de um grafo.
- Matriz de covariância
- Matriz simétrica que descreve variâncias e covariâncias entre variáveis aleatórias.
- Mínimos quadrados
- Método de aproximação que minimiza a soma dos quadrados dos erros.
- Multiplicidade algébrica
- Número de vezes que um autovalor aparece como raiz do polinômio característico.
- Multiplicidade geométrica
- Dimensão do autoespaço associado a um autovalor.
- NLP
- Sigla de Natural Language Processing, ou processamento de linguagem natural.
- Núcleo
- Conjunto dos vetores enviados ao vetor nulo por uma transformação linear.
- PCA
- Sigla de Principal Component Analysis, técnica de redução de dimensionalidade baseada em autovetores.
- Pivô
- Elemento de referência usado no escalonamento de uma matriz para eliminar entradas em sua coluna.
- Pivotamento
- Troca controlada de linhas ou colunas para melhorar estabilidade numérica durante eliminação.
- Polinômio característico
- Polinômio $p(\lambda)=\det(A-\lambda I)$, cujas raízes são os autovalores da matriz.
- Polinômio minimal
- Polinômio mónico de menor grau que anula a matriz quando nela é avaliado.
- Posto
- Dimensão da imagem de uma transformação linear, ou do espaço gerado pelas colunas de uma matriz.
- Produto interno
- Operação que associa dois vetores a um número real e permite definir ângulo, norma e ortogonalidade.
- Produto cartesiano
- Conjunto de todas as tuplas formadas pela escolha de um elemento de cada conjunto dado.
- Projeção ortogonal
- Melhor aproximação de um vetor por outro vetor pertencente a uma reta ou subespaço.
- QR
- Sigla da fatoração que decompõe uma matriz em uma parte ortogonal e outra triangular.
- Reta ou plano passando pela origem
- Conjunto geométrico que contém o vetor nulo; em muitos casos, isso é condição para ser subespaço.
- Retro-substituição
- Procedimento usado após o escalonamento para resolver um sistema triangular de baixo para cima.
- Sistema homogêneo
- Sistema linear cujo vetor do lado direito é nulo.
- Sistema incompatível
- Sistema linear que não possui solução.
- Sistema iterativo
- Método que produz aproximações sucessivas para a solução de um problema.
- Span
- Menor subespaço que contém um conjunto de vetores; conjunto de todas as suas combinações lineares.
- Teorema do posto e da nulidade
- Resultado que relaciona dimensão do domínio, dimensão da imagem e dimensão do núcleo.
- Transformada de Fourier
- Transformação linear que representa sinais em termos de frequências.
- Wavelets
- Família de funções e transformações usadas para análise multiescala de sinais e imagens.
Referências: